南京市江宁区秣周东路9号

新闻详情
清湛会同江苏省人工智能学会、中国人工智能智能学会认知专委会等多家单位共同发布2023年度MLOps产业图谱
本文是根据《2023世界人工智能大会"新AI,新制造"2023 AI+制造产业论坛》上清湛人工智能研究院执行院长杨磊博士的演讲整理而成。这个报告是我们酝酿了几个月后会同一些对于这个话题关注的同仁共同撰写的。
1. AIGC时代AI存在的社会性歧视
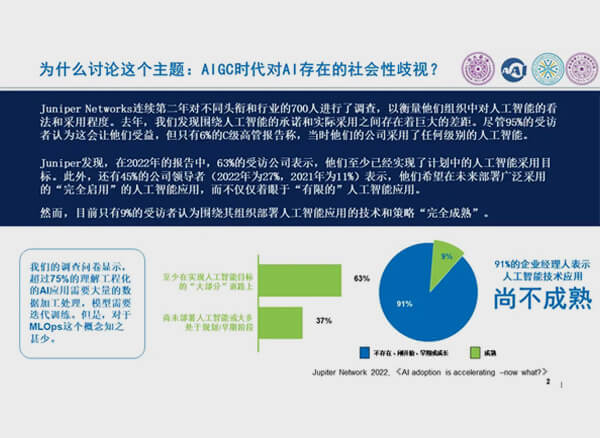
我们知道,虽然我们在过去人工智能发展的60年历史,无数的专家、学者、工程技术人员做了很多努力。但是事实上,从整个产业层面上来看,对人工智能技术的应用并不如人意。我们可以看到2022年Jupiter的行业调研报告中指出仍然有超过91%的企业,认为人工智能技术尚不成熟。虽然有超过一半以上的企业认为人工智能在未来具有较大的潜力。即使在生成式人工智能时代,人工智能技术也存在着普遍的技术性的社会性歧视。
我们一直在思考这个问题是什么原因造成的,同比与物理学、数学、化学,人工智能属于新应用科学的前端。相比于机械、汽车、自动化等工程学科,人工智能又充满了太多的未知的和未解之谜。事实上,整个人类未来人工智能技术的高速发展或者是给社会带来的红利都充满了巨大的期望。但是,现实的骨感让我们不得不不断思索。
2.工业AI vs 消费AI
我们怎么把AI的新发现变成实际可用的东西,而不是仅仅用来聊天的生成各种茶余饭后话题的工具。尤其是在制造业,我们怎么使用人工智能技术。

吴恩达教授最近在接受采访时谈到了这一点,原因有很多:在消费软件互联网中,我们可以训练一些机器学习模型来服务十亿用户,而在制造业中,可能有10000个制造商构建10000个定制产品人工智能模型。这意味着什么,例如,对于翻译,可以构建了一个可以为数百万用户服务的单一语言模型。但在缺陷检测中,无论检测汽车零件中的缺陷还是智能手机屏幕中的缺陷,都有一个使用非常不同的数据,需要使用非常不同的人工智能方法。因此在制造业中的应用人工智能技术,高度定制化的、高度个性化的人工智能方法是必要的。
因此,与消费者世界或通用软件行业中的人工智能有通用的人工智能。但在工业人工智能中,制造业中使用的人工智能它更具有行业特定性。互联网上有数百万来自人们活动的用户数据,可以使用它们来训练人工智能模型,但在工业案例中,小样本数据、稀疏数据是一直存在着的挑战。
3.博伊德迭代法则
是否有人知道博伊德迭代定律?

博伊德是美国二战时期的飞行员和飞机设计师,他从米格和f86之间的缠斗中发现了一个非常有趣的事实。认为米格在各方面都优越,但是十次被f86击败九次,他分析了这一点,发现关键在于方向盘,所以在缠斗中重要的是观察、了解情况、计划、并迅速采取行动非常重要。但在驾驶米格战斗机的情况下,它需要更多的体力来进行转向,进行迭代非常困难。
因此,博伊德得出了这一原则:迭代的速度,质量的速度。这一原则在不同的领域中具有非常重要的地位。例如,敏捷开发在是软件开发领域非常重要的原则,它在机器学习开发中也非常相似。因此,我们查看机器学习/深度学习开发和操作的整个过程。从问题定义开始,数据收集、分析和建模,最后进行部署和操作。我们的期望是,这可以线性地一步步完成,但实际上需要不断的返回到前一阶段进行迭代。例如,当意识到需要重新定义问题、当进行数据收集和分析时,有些数据或者操作步骤需要改变,或者当意识到没有足够的数据或标签来进行机器学习建模等时,需要返回数据收集环节。所以,这个机器学习/深度学习系统整个研发过程高度非线性,反馈循环频繁。关键挑战来自于开发环境和运行环境脱节,其原因是运行环境比开发环境复杂得多。所以,我们对人工智能系统的期望包括只是机器学习/深度学习模型和操作代码,但现实是需要数据收集、数据验证、资源管理配置等等大量的工作。
博伊德认为,空战中取胜的主要决定因素不是观察、定向、计划以及更好地执行,而是观察、定向、计划以及更快地执行。换句话说,能不能取胜就看人们能够多快地执行迭代。这就是所谓的"博伊德迭代法则":迭代的速度胜过迭代的质量。英文原句为:Speed of iteration beats quality of iteration。
4.代码其实只是AI系统的非常小的一个构成部分
有过面向工程开发AI系统经验的工程师,经常有很深的体会。花在不断的组装各种开源环境,数据标注,参数调节的时间要远远超过代码编写的时间。而且,系统的调整是一个不断往复的阶段。就像靠松散的小树枝堆砌的巴比塔,新的树枝的添入,对最大的贡献是产生更多的不稳定性。AI系统的开发更面临同样的问题。
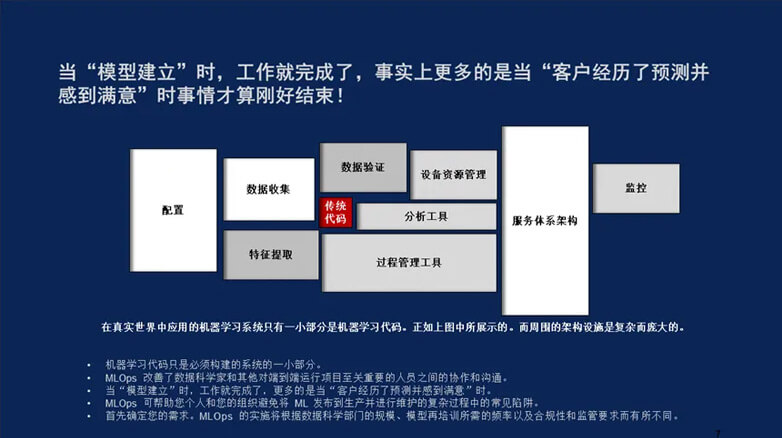
谷歌的工程师最早意识到这个问题,缺乏有效的工具。会让你不断的陷入。这个死循环。
5.什么是MLOPS?
事实上,MLOps教父谷歌大脑负责人的d. sculley在早2016年出版的《机器学习隐藏的技术债》一文中最早提出了这个概念。如果我们真的把一些AI技术或者所谓的AI算法应用到实际工程中,其实会遇到大量的问题。谷歌的工程师们基于大量的机器学习系统构建和维护经验,写了这篇论文。

机器学习操作 (MLOps) 基于可提高工作流效率的 DevOps 原理和做法。例如持续集成、持续交付和持续部署。MLOps 将这些原理应用到机器学习过程,其目标是:
- 更快地试验和开发模型
- 更快地将模型部署到生产环境
- 质量保证
自从2015年MLOps一词提出,迄今已经6年。MLOps解决方案的市场预计到2025年将达到40亿美元。
在Chatgpt出现了耀眼的光芒的同时,也出现了无数个围绕大模型训练耀眼的小星星,比如说Databrics、huggingface等。他们各种大模型工具提供了工程实践落地的有效支持。
6.MLOPS技术框架技术图谱
MLOPS的从理念到落地,不断迭代,基于DevOps已经逐渐成熟。形成了一套约定的框架。
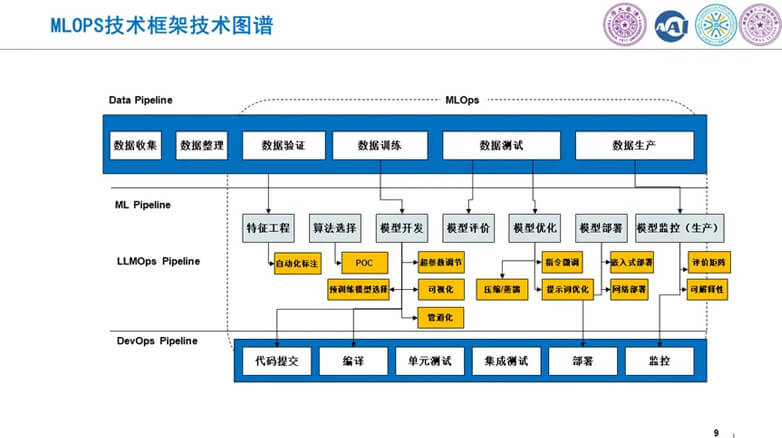
围绕特征工程、数据整理、数据验证、数据训练等。尤其是大模型出现后,新的工具体系又逐渐生成,比如预训练模型的选择,指令微调,提示词优化等。让普通的工程师可以快速使用到大模型这一前沿技术。
7.LLMOps成为MLOps当前最热的前沿方向?
虽然生成式AI为企业提供了巨大的优势,但在被广泛的行业使用之前,仍有许多障碍。LLM,尤其是最新的模型,系统开销大、推理时间慢,需要复杂而昂贵的基础设施才能运行。只有拥有经验丰富、拥有大量资源的ML团队的公司才能将此类模型推向市场。OpenAI、Anthropic和Cohere已经筹集了数十亿美元的资金来生产这些模型。
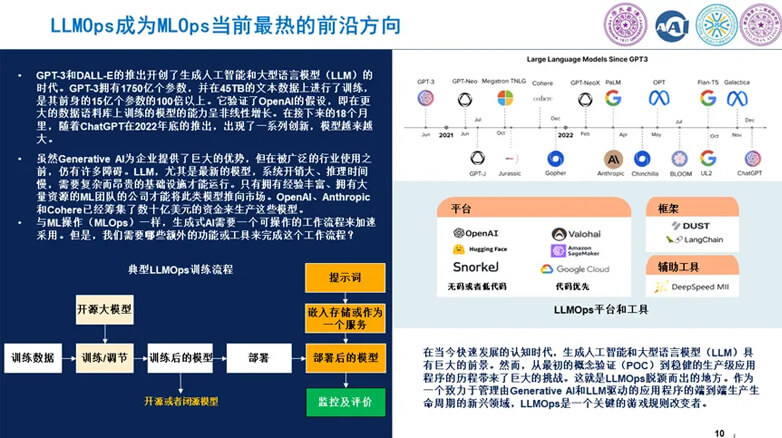
与ML操作(MLOps)一样,生成式AI需要一个可操作的工作流程来加速采用。但是,我们需要哪些额外的功能或工具来完成这个工作流程?
如今,我们目睹了新一代人工智能技术平台——大型语言模型(LLMs)的问世。与预训练语言学习模型(pre-LLM)相比,大型语言模型具有独特的工作流程、技能组件和发展潜能,代表了人工智能的新范式。通过API或者开源,人们可以很容易获得大量预训练模型,这完全改变了人工智能产品。因此,注定会出现一套新的工具和基础设施。
我们预测LLMOps将成为新的流行趋势,它代表着新一代人工智能的镐头和铲子。以新一代LLMOps产品为例,包括基础模型微调工具、无代码LLM部署、GPU访问与优化、提示词实验、提示词链以及数据合成与数据增强。
8.数据已经成为重要的生产要素
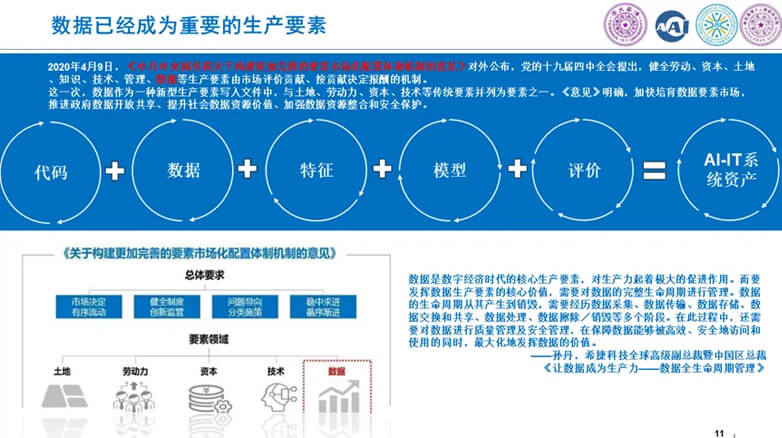
我们知道AI时代是数据、算法和算力推动的。但是事实上,反过来,对数据的高效使用又推动了整个产业对于数据价值的认识。数据已经成为是数字经济时代的核心生产要素,对生产力起着极大的促进作用。
那和传统IT软件相比,AI-IT系统资产事实上由传统的仅仅是"代码"构成转变成为"代码"+“数据”+“特征”+“模型”+“评价"而形成的一个更为复杂的系统。这个转变,使得整个软件行业未来对于开发者的技能又进行了重复的定义。
MLOps对于集成式、端对端的开发范式,为数据要素的生产管理、安全管理提供了极大的保障。数据所有者不需要把数据暴露给第三方的同时,又丢失了数据的所有权。所有数据加工生产过程,都在有序、安全的条件下进行。
9.MLOPS处于市场高速发展期
MLOps市场正处于高速发展期,预计未来几年将保持快速增长。随着企业对AI技术的需求不断增加,MLOps工具和平台的市场需求也在不断扩大。